
一、定义
Redux is a predictable state container for JavaScript apps.,其中 predictable 和 state container 体现了它的作用。
那么如何来理解可预测化的呢?
这里会有一些函数式编程方面的思想,在 Redux 中 reducer 函数是一个纯函数,相同输入一定会是一致的输出,所以确定输入的 state 那么 reducer 函数输出的 state 一定是可以被预测的,因为它只会进行单纯的计算,保证正确的输出。
状态容器又是什么?
说明 Redux 有一个专门管理 state 的地方,就是 Store,并且一般情况下是唯一的,应用中所有 state 形成的一颗状态树就是 Store。Redux 由 Flux 演变而来,但受 Elm 的启发,避开了 Flux 的复杂性,我们看看其数据流向:
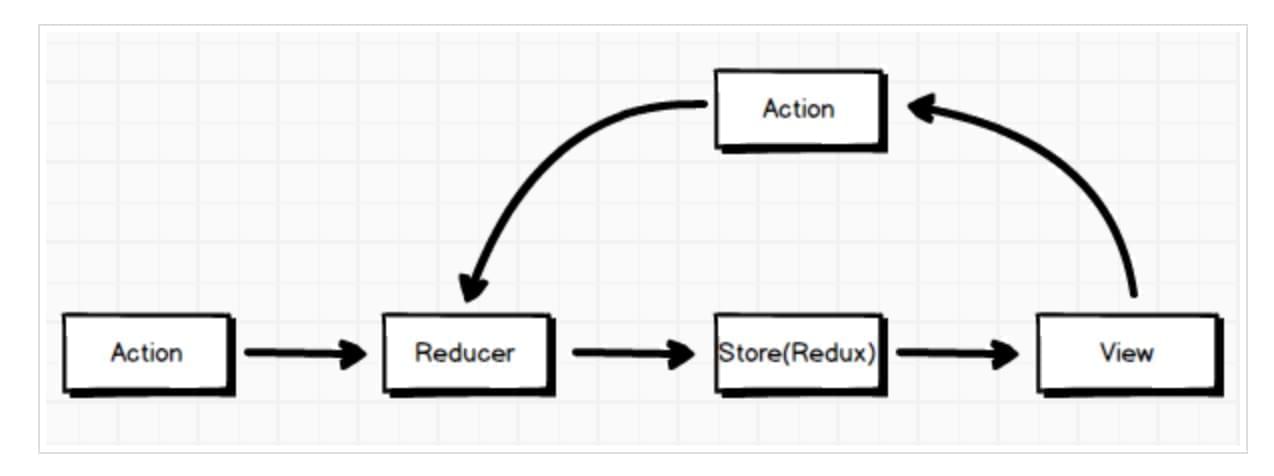
不同于 Flux 架构,Redux 中没有 dispatcher 这个概念,并且 Redux 设想你永远不会变动你的数据,你应该在 reducer 中返回新的对象来作为应用的新状态。但是它们都可以用(state, action) => newState 来表述其核心思想,所以 Redux 可以被看成是 Flux 思想的一种实现,但是在细节上会有一些差异。
二、原则
- 应用中所有的 state 都以一个 object tree 的形式存储在一个单一的 store 中;
- 唯一能改变 store 的方法是触发 Action,Action 是动作行为的抽象;
- 为了描述 Action 如何改变 State 树,需要编写 reducer 函数;
function testReducer(state, action) {
switch (action.type) {
case ACTION_TYPE: // calc...
return newState;
default:
return state;
}
return newState;
}state 是不可修改的,所以返回的新 state 应该是基于输入 state 副本的修改,而不是直接修改 state 后的返回。可见:
- 单一数据源,store:整个应用的 state 被存放在一棵 Object tree 树,并且整个 object tree 只存在唯一的一个 store 中;
- State 是只读的:唯一能改变 State 的方法是触发 Action;
- 使用纯函数来实现 State 归并操作,reducer:传入待修改的 state 和一个告知 reducer 如何修改 state 的 action,reducer 将返回 action 规则对应下操作后的新的 state;
reducer(state, action) => new state
三、数据流
严格的单向数据流是 Redux 设计的核心,Redux 应用数据的生命周期遵循下面 4 个步骤:
调用 store.dispatch(action), 可以在任何地方进行;
Redux store 调用传入的 reducer 函数,并且将当前的 state 树与 action 传入。reducer 是纯函数,只用于计算下一个 state,它应该是完全可被预测的,相同的输入必定会有相同的输出,不能有副作用的操作,如 API 的调用或者路由跳转,这些应该都是在 dispatch 前产生;
根 reducer 将多个子 reducer 输出合并成一个单一的 state 树;
Redux store 保存了根 reducer 返回的完整的 state 树。
新的 state 树就是应用的下一个状态,现在就可以根据新的 state tree 来渲染 UI
- React 有 props 和 state: props 意味着父级分发下来的属性,state 意味着组件内部可以自行管理的状态,并且整个 React 没有数据向上回溯的能力,也就是说数据只能单向向下分发,或者自行内部消化。
理解这个是理解 React 和 Redux 的前提。 - 一般构建的 React 组件内部可能是一个完整的应用,它自己工作良好,你可以通过属性作为 API 控制它。但是更多的时候发现 React 根本无法让两个组件互相交流,使用对方的数据。
然后这时候不通过 DOM 沟通(也就是 React 体制内)解决的唯一办法就是提升 state,将 state 放到共有的父组件中来管理,再作为 props 分发回子组件。 - 子组件改变父组件 state 的办法只能是通过 onClick 触发父组件声明好的回调,也就是父组件提前声明好函数或方法作为契约描述自己的 state 将如何变化,再将它同样作为属性交给子组件使用。
这样就出现了一个模式:数据总是单向从顶层向下分发的,但是只有子组件回调在概念上可以回到 state 顶层影响数据。这样 state 一定程度上是响应式的。 - 为了面临所有可能的扩展问题,最容易想到的办法就是把所有 state 集中放到所有组件顶层,然后分发给所有组件。
- 为了有更好的 state 管理,就需要一个库来作为更专业的顶层 state 分发给所有 React 应用,这就是 Redux。让我们回来看看重现上面结构的需求:
a. 需要回调通知 state (等同于回调参数) -> action
b. 需要根据回调处理 (等同于父级方法) -> reducer
c. 需要 state (等同于总状态) -> store
对 Redux 来说只有这三个要素:
a. action 是纯声明式的数据结构,只提供事件的所有要素,不提供逻辑。
b. reducer 是一个匹配函数,action 的发送是全局的:所有的 reducer 都可以捕捉到并匹配与自己相关与否,相关就拿走 action 中的要素进行逻辑处理,修改 store 中的状态,不相关就不对 state 做处理原样返回。
c. store 负责存储状态并可以被 react api 回调,发布 action.
当然一般不会直接把两个库拿来用,还有一个 binding 叫 react-redux, 提供一个 Provider 和 connect。很多人其实看懂了 redux 卡在这里。
a. Provider 是一个普通组件,可以作为顶层 app 的分发点,它只需要 store 属性就可以了。它会将 state 分发给所有被 connect 的组件,不管它在哪里,被嵌套多少层。
b. connect 是真正的重点,它是一个科里化函数,意思是先接受两个参数(数据绑定 mapStateToProps 和事件绑定 mapDispatchToProps),再接受一个参数(将要绑定的组件本身):
mapStateToProps:构建好 Redux 系统的时候,它会被自动初始化,但是你的 React 组件并不知道它的存在,因此你需要分拣出你需要的 Redux 状态,所以你需要绑定一个函数,它的参数是 state,简单返回你关心的几个值。
mapDispatchToProps:声明好的 action 作为回调,也可以被注入到组件里,就是通过这个函数,它的参数是 dispatch,通过 redux 的辅助方法 bindActionCreator 绑定所有 action 以及参数的 dispatch,就可以作为属性在组件里面作为函数简单使用了,不需要手动 dispatch。这个 mapDispatchToProps 是可选的,如果不传这个参数 redux 会简单把 dispatch 作为属性注入给组件,可以手动当做 store.dispatch 使用。这也是为什么要科里化的原因。
做好以上流程 Redux 和 React 就可以工作了。
简单地说就是:
- 顶层分发状态,让 React 组件被动地渲染。
- 监听事件,事件有权利回到所有状态顶层影响状态。